Publications
2024
2024
-
 Map It Anywhere (MIA): Empowering Bird’s Eye View Mapping using Large-scale Public DataCherie Ho*, Jiaye Zou*, Omar Alama*, Sai Mitheran Jagadesh Kumar, Benjamin Chiang, Taneesh Gupta, Chen Wang, and 3 more authorsNeurIPS, 2024
Map It Anywhere (MIA): Empowering Bird’s Eye View Mapping using Large-scale Public DataCherie Ho*, Jiaye Zou*, Omar Alama*, Sai Mitheran Jagadesh Kumar, Benjamin Chiang, Taneesh Gupta, Chen Wang, and 3 more authorsNeurIPS, 2024Top-down Bird’s Eye View (BEV) maps are a popular representation for ground robot navigation due to their richness and flexibility for downstream tasks. While recent methods have shown promise for predicting BEV maps from First-Person View (FPV) images, their generalizability is limited to small regions captured by current autonomous vehicle-based datasets. In this context, we show that a more scalable approach towards generalizable map prediction can be enabled by using two large-scale crowd-sourced mapping platforms, Mapillary for FPV images and OpenStreetMap for BEV semantic maps. We introduce Map It Anywhere (MIA), a data engine that enables seamless curation and modeling of labeled map prediction data from existing open-source map platforms. Using our MIA data engine, we display the ease of automatically collecting a 1.2 million FPV & BEV pair dataset encompassing diverse geographies, landscapes, environmental factors, camera models & capture scenarios. We further train a simple camera model-agnostic model on this data for BEV map prediction. Extensive evaluations using established benchmarks and our dataset show that the data curated by MIA enables effective pretraining for generalizable BEV map prediction, with zero-shot performance far exceeding baselines trained on existing datasets by 35%. Our analysis highlights the promise of using large-scale public maps for developing & testing generalizable BEV perception, paving the way for more robust autonomous navigation.
-
 TartanAviation: Image, Speech, and ADS-B Trajectory Datasets for Terminal Airspace OperationsJay Patrikar, Joao Dantas, Brady Moon, Milad Hamidi, Sourish Ghosh, Nikhil Keetha, and othersArXiv, 2024
TartanAviation: Image, Speech, and ADS-B Trajectory Datasets for Terminal Airspace OperationsJay Patrikar, Joao Dantas, Brady Moon, Milad Hamidi, Sourish Ghosh, Nikhil Keetha, and othersArXiv, 2024 -
 SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAMNikhil Keetha, Jay Karhade, Krishna Murthy Jatavallabhula, Gengshan Yang, Sebastian Scherer, Deva Ramanan, and Jonathon LuitenCVPR, 2024
SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAMNikhil Keetha, Jay Karhade, Krishna Murthy Jatavallabhula, Gengshan Yang, Sebastian Scherer, Deva Ramanan, and Jonathon LuitenCVPR, 2024Dense simultaneous localization and mapping (SLAM) is pivotal for embodied scene understanding. Recent work has shown that 3D Gaussians enable high-quality reconstruction and real-time rendering of scenes using multiple posed cameras. In this light, we show for the first time that representing a scene by 3D Gaussians can enable dense SLAM using a single unposed monocular RGB-D camera. Our method, SplaTAM, addresses the limitations of prior radiance field-based representations, including fast rendering and optimization, the ability to determine if areas have been previously mapped, and structured map expansion by adding more Gaussians. We employ an online tracking and mapping pipeline while tailoring it to specifically use an underlying Gaussian representation and silhouette-guided optimization via differentiable rendering. Extensive experiments show that SplaTAM achieves up to 2X state-of-the-art performance in camera pose estimation, map construction, and novel-view synthesis, demonstrating its superiority over existing approaches, while allowing real-time rendering of a high-resolution dense 3D map.



2023
2023
-
 Toward General-Purpose Robots via Foundation Models: A Survey and Meta-AnalysisYafei Hu*, Quanting Xie*, Vidhi Jain*, Jonathan Francis, Jay Patrikar, Nikhil Keetha, and othersArXiv, 2023
Toward General-Purpose Robots via Foundation Models: A Survey and Meta-AnalysisYafei Hu*, Quanting Xie*, Vidhi Jain*, Jonathan Francis, Jay Patrikar, Nikhil Keetha, and othersArXiv, 2023 -
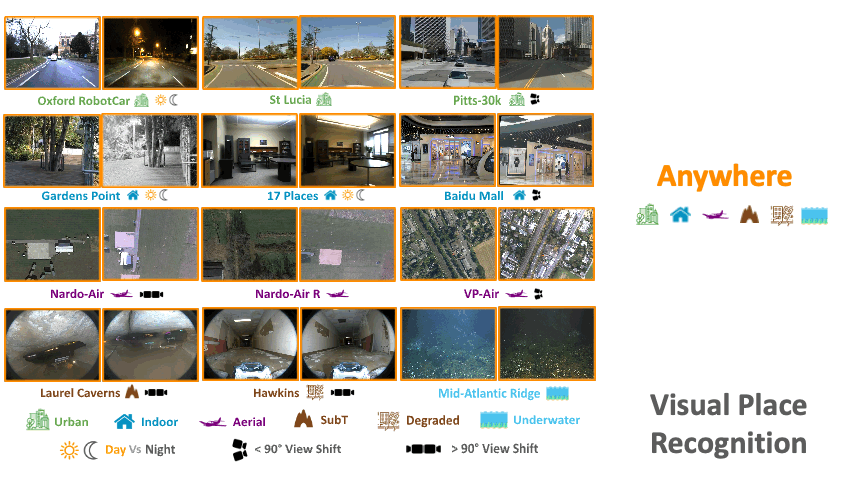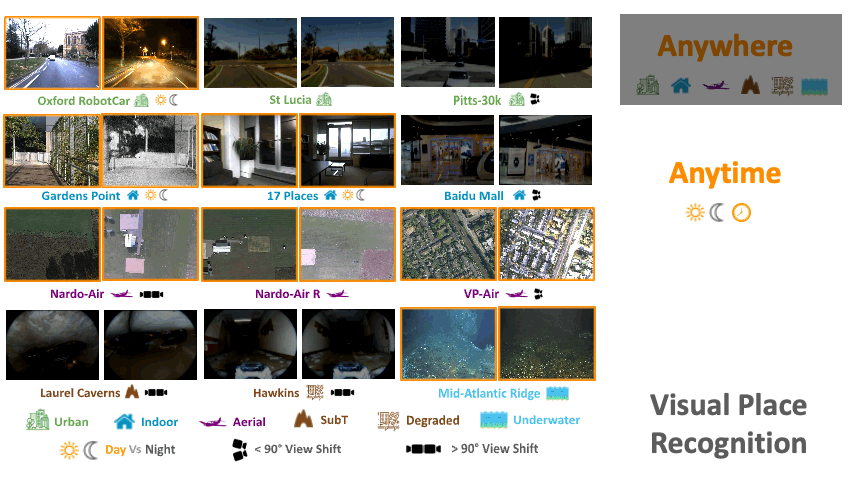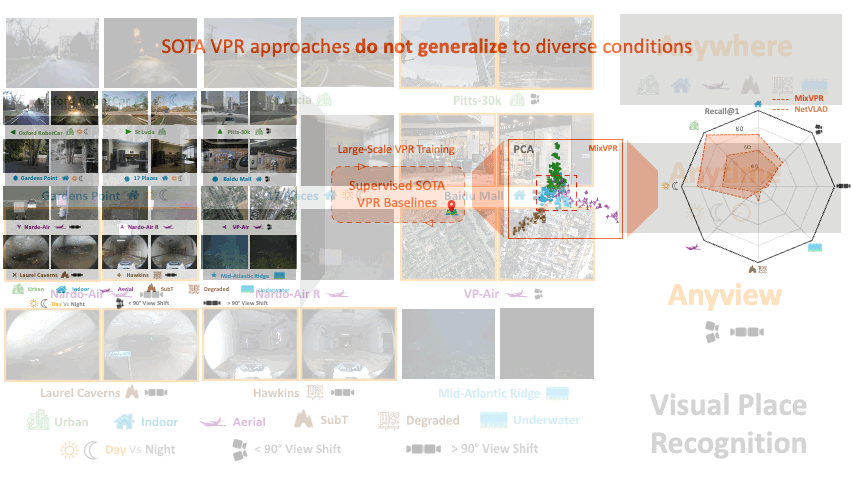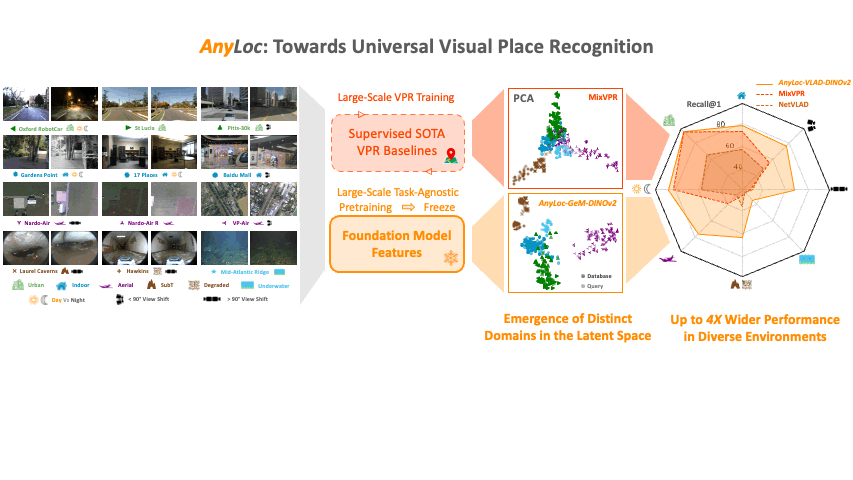 AnyLoc: Towards Universal Visual Place RecognitionNikhil Keetha*, Avneesh Mishra*, Jay Karhade*, Krishna Murthy Jatavallabhula, Sebastian Scherer, Madhava Krishna, and Sourav GargIEEE RA-L, 2023
AnyLoc: Towards Universal Visual Place RecognitionNikhil Keetha*, Avneesh Mishra*, Jay Karhade*, Krishna Murthy Jatavallabhula, Sebastian Scherer, Madhava Krishna, and Sourav GargIEEE RA-L, 2023Visual Place Recognition (VPR) is vital for robot localization. To date, the most performant VPR approaches are environment- and task-specific: while they exhibit strong performance in structured environments (predominantly urban driving), their performance degrades severely in unstructured environments, rendering most approaches brittle to robust real-world deployment. In this work, we develop a universal solution to VPR – a technique that works across a broad range of structured and unstructured environments (urban, outdoors, indoors, aerial, underwater, and subterranean environments) without any re-training or fine-tuning. We demonstrate that general-purpose feature representations derived from off-the-shelf self-supervised models with no VPR-specific training are the right substrate upon which to build such a universal VPR solution. Combining these derived features with unsupervised feature aggregation enables our suite of methods, AnyLoc, to achieve up to 4X significantly higher performance than existing approaches. We further obtain a 6% improvement in performance by characterizing the semantic properties of these features, uncovering unique domains which encapsulate datasets from similar environments. Our detailed experiments and analysis lay a foundation for building VPR solutions that may be deployed anywhere, anytime, and across anyview. We encourage the readers to explore our project page and interactive demos: https://anyloc.github.io/.
-
 FoundLoc: Vision-based Onboard Aerial Localization in the WildYao He*, Ivan Cisneros*, Nikhil Keetha, Jay Patrikar, Zelin Ye, Ian Higgins, Yaoyu Hu, and 2 more authorsArxiv, 2023
FoundLoc: Vision-based Onboard Aerial Localization in the WildYao He*, Ivan Cisneros*, Nikhil Keetha, Jay Patrikar, Zelin Ye, Ian Higgins, Yaoyu Hu, and 2 more authorsArxiv, 2023Robust and accurate localization for Unmanned Aerial Vehicles (UAVs) is an essential capability to achieve autonomous, long-range flights. Current methods either rely heavily on GNSS, face limitations in visual-based localization due to appearance variances and stylistic dissimilarities between camera and reference imagery, or operate under the assumption of a known initial pose. In this paper, we developed a GNSS-denied localization approach for UAVs that harnesses both Visual-Inertial Odometry (VIO) and Visual Place Recognition (VPR) using a foundation model. This paper presents a novel vision-based pipeline that works exclusively with a nadir-facing camera, an Inertial Measurement Unit (IMU), and pre-existing satellite imagery for robust, accurate localization in varied environments and conditions. Our system demonstrated average localization accuracy within a 20-meter range, with a minimum error below 1 meter, under real-world conditions marked by drastic changes in environmental appearance and with no assumption of the vehicle’s initial pose. The method is proven to be effective and robust, addressing the crucial need for reliable UAV localization in GNSS-denied environments, while also being computationally efficient enough to be deployed on resource-constrained platforms.
-
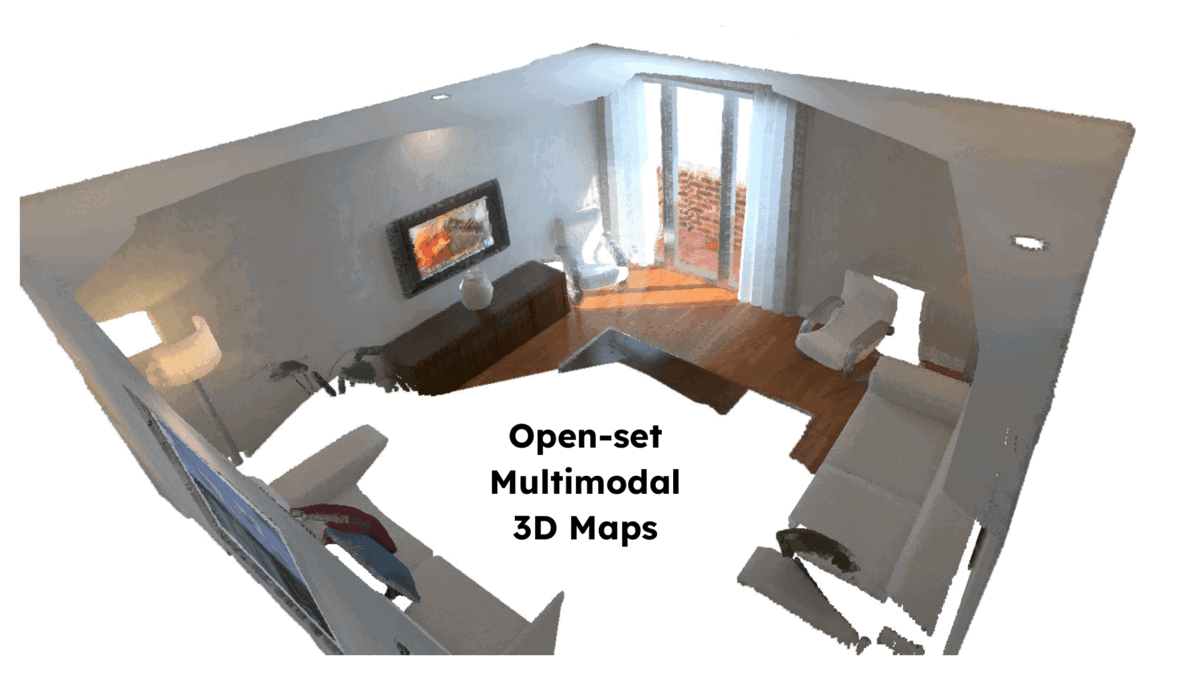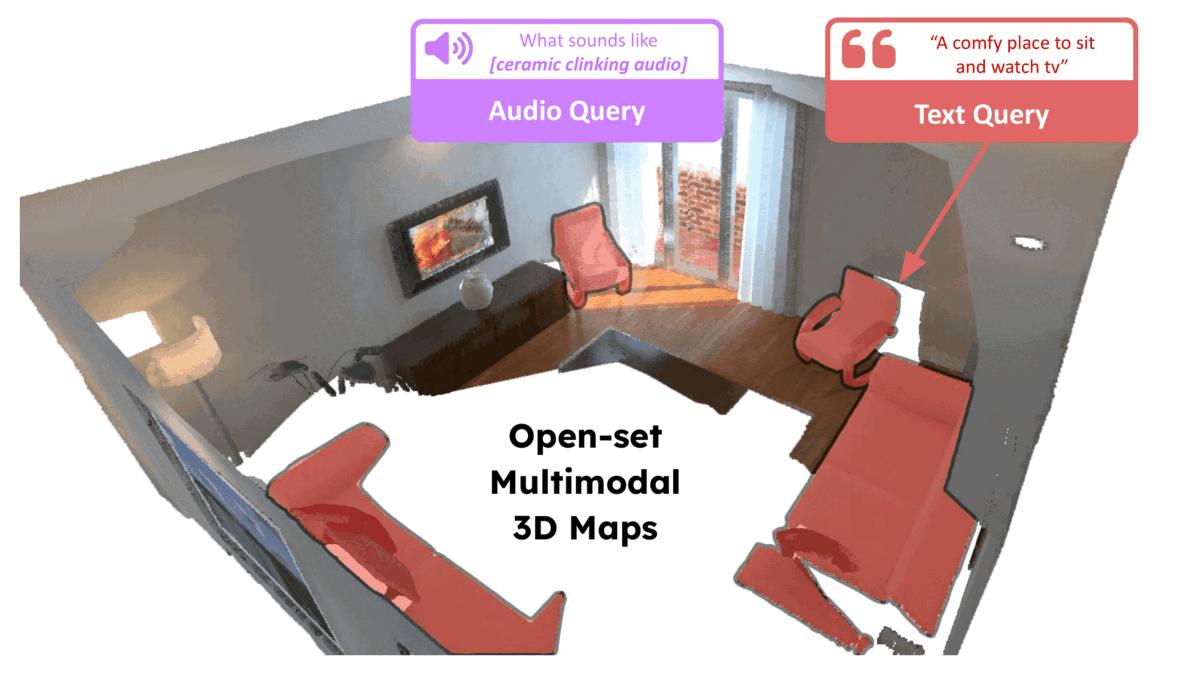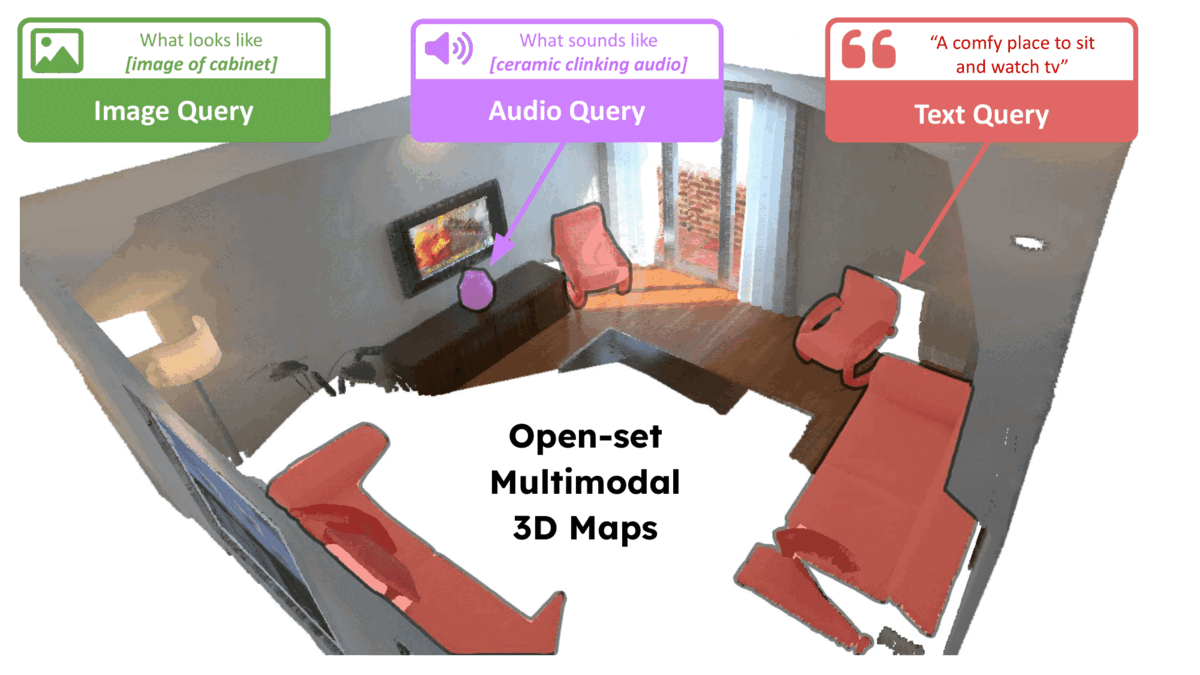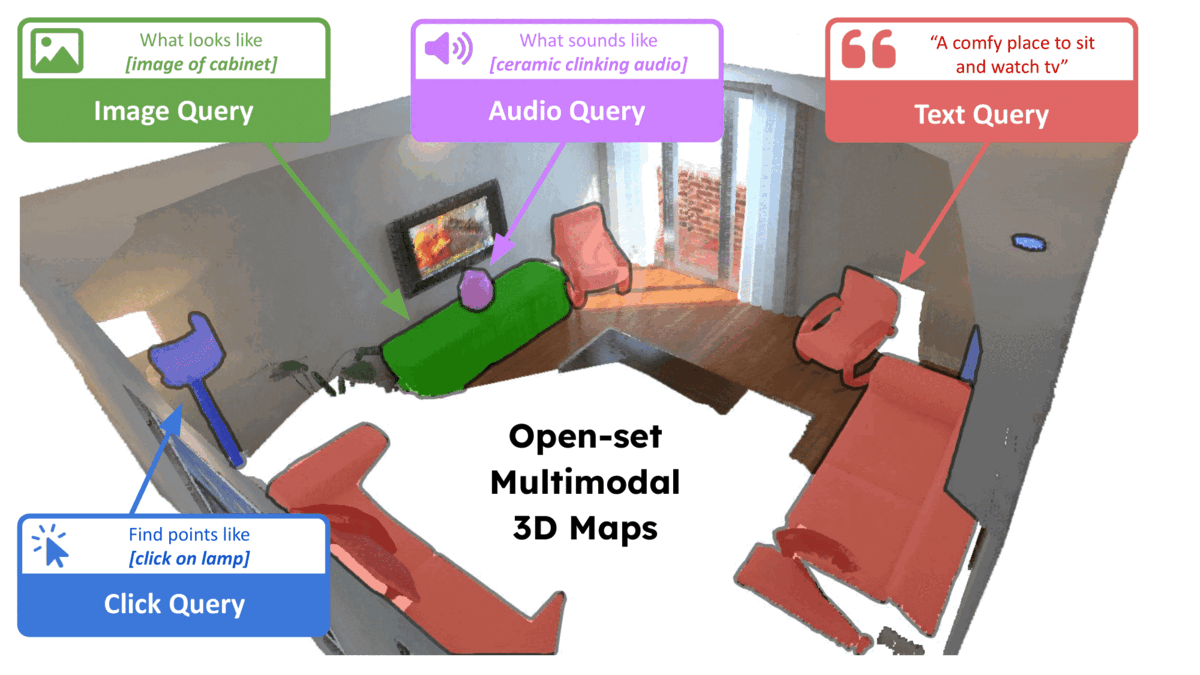 ConceptFusion: Open-set Multimodal 3D MappingKrishna Murthy Jatavallabhula, and othersRSS, 2023
ConceptFusion: Open-set Multimodal 3D MappingKrishna Murthy Jatavallabhula, and othersRSS, 2023Building 3D maps of the environment is central to robot navigation, planning, and interaction with objects in a scene. Most existing approaches that integrate semantic concepts with 3D maps largely remain confined to the closed-set setting: they can only reason bout a finite set of concepts, pre-defined at training time. Further, these maps can only be queried using class labels, or in recent work, using text prompts. We address both these issues with ConceptFusion, a scene representation that is: (i) fundamentally open-set, enabling reasoning beyond a closed set of concepts (ii) inherently multi-modal, enabling a diverse range of possible queries to the 3D map, from language, to images, to audio, to 3D geometry, all working in concert. ConceptFusion leverages the open-set capabilities of today’s foundation models pre-trained on internet-scale data to reason about concepts across modalities such as natural language, images, and audio. We demonstrate that pixel-aligned open-set features can be fused into 3D maps via traditional SLAM and multi-view fusion approaches. This enables effective zero-shot spatial reasoning, not needing any additional training or finetuning, and retains long-tailed concepts better than supervised approaches, outperforming them by more than 40% margin on 3D IoU. We extensively evaluate ConceptFusion on a number of real-world datasets, simulated home environments, a real-world tabletop manipulation task, and an autonomous driving platform. We showcase new avenues for blending foundation models with 3D open-set multimodal mapping.




2022
2022
-
 AirObject: A Temporally Evolving Graph Embedding for Object IdentificationCVPR, 2022
AirObject: A Temporally Evolving Graph Embedding for Object IdentificationCVPR, 2022Object encoding and identification are vital for robotic tasks such as autonomous exploration, semantic scene understanding, and re-localization. Previous approaches have attempted to either track objects or generate descriptors for object identification. However, such systems are limited to a "fixed" partial object representation from a single viewpoint. In a robot exploration setup, there is a requirement for a temporally "evolving" global object representation built as the robot observes the object from multiple viewpoints. Furthermore, given the vast distribution of unknown novel objects in the real world, the object identification process must be class-agnostic. In this context, we propose a novel temporal 3D object encoding approach, dubbed AirObject, to obtain global keypoint graph-based embeddings of objects. Specifically, the global 3D object embeddings are generated using a temporal convolutional network across structural information of multiple frames obtained from a graph attention-based encoding method. We demonstrate that AirObject achieves the state-of-the-art performance for video object identification and is robust to severe occlusion, perceptual aliasing, viewpoint shift, deformation, and scale transform, outperforming the state-of-the-art single-frame and sequential descriptors. To the best of our knowledge, AirObject is one of the first temporal object encoding methods.

2021
2021
-
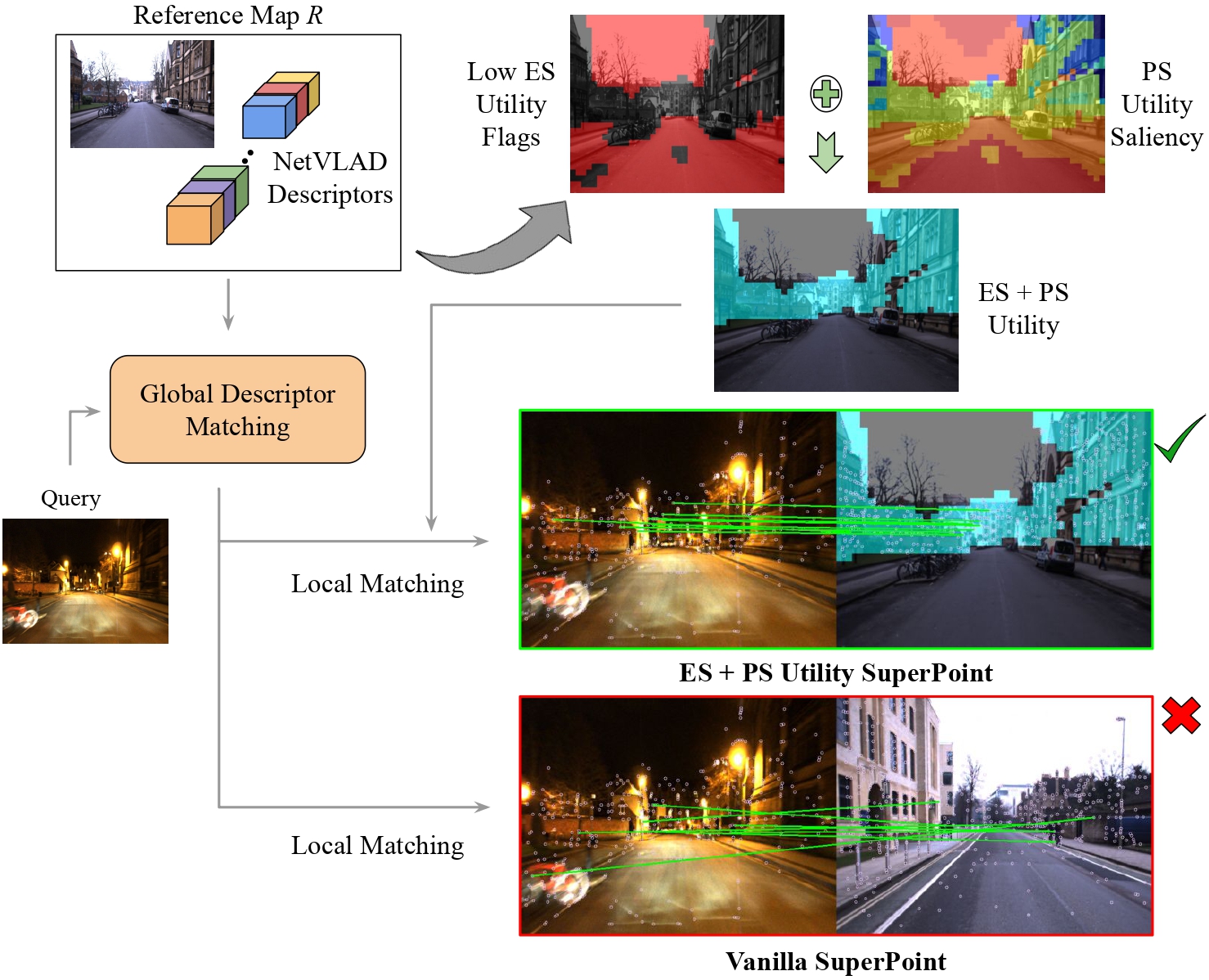 A Hierarchical Dual Model of Environment- and Place-specific Utility for Visual Place RecognitionNikhil Keetha, Michael Milford, and Sourav GargIEEE RA-L & IROS, 2021
A Hierarchical Dual Model of Environment- and Place-specific Utility for Visual Place RecognitionNikhil Keetha, Michael Milford, and Sourav GargIEEE RA-L & IROS, 2021Visual Place Recognition (VPR) approaches have typically attempted to match places by identifying visual cues, image regions or landmarks that have high “utility” in identifying a specific place. But this concept of utility is not singular - rather it can take a range of forms. In this paper, we present a novel approach to deduce two key types of utility for VPR: the utility of visual cues ‘specific’ to an environment, and to a particular place. We employ contrastive learning principles to estimate both the environment- and place-specific utility of Vector of Locally Aggregated Descriptors (VLAD) clusters in an unsupervised manner, which is then used to guide local feature matching through keypoint selection. By combining these two utility measures, our approach achieves state-of-the-art performance on three challenging benchmark datasets, while simultaneously reducing the required storage and compute time. We provide further analysis demonstrating that unsupervised cluster selection results in semantically meaningful results, that finer grained categorization often has higher utility for VPR than high level semantic categorization (e.g. building, road), and characterise how these two utility measures vary across different places and environments.

2020
2020
-
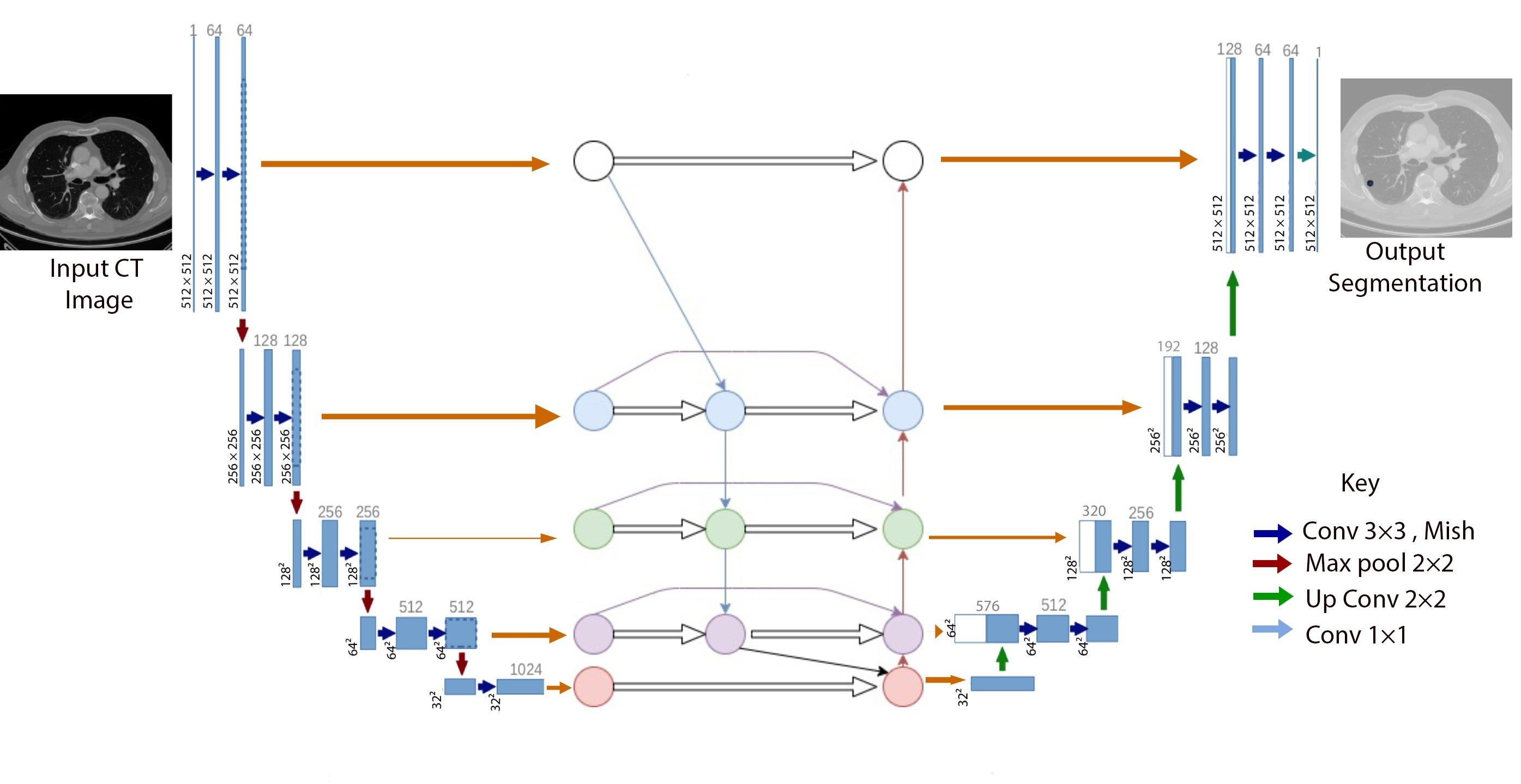 U-Det: A bidirectional feature network based U-Net architecture for lung nodule segmentationNikhil Keetha, Samson P. A. B., and Annavarapu C. S. R.MDPI Diagnostics, 2020
U-Det: A bidirectional feature network based U-Net architecture for lung nodule segmentationNikhil Keetha, Samson P. A. B., and Annavarapu C. S. R.MDPI Diagnostics, 2020Early diagnosis and analysis of lung cancer involve a precise and efficient lung nodule segmentation in computed tomography (CT) images. However, the anonymous shapes, visual features, and surroundings of the nodule in the CT image pose a challenging problem to the robust segmentation of the lung nodules. This article proposes U-Det, a resource-efficient model architecture, which is an end to end deep learning approach to solve the task at hand. It incorporates a Bi-FPN (bidirectional feature network) between the encoder and decoder. Furthermore, it uses Mish activation function and class weights of masks to enhance segmentation efficiency. The proposed model is extensively trained and evaluated on the publicly available LUNA-16 dataset consisting of 1186 lung nodules. The U-Det architecture outperforms the existing U-Net model with the Dice similarity coefficient (DSC) of 82.82% and achieves results comparable to human experts.
